
정화 코딩
[논문 리뷰] Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time 본문
[논문 리뷰] Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
jungh150c 2025. 11. 18. 12:07https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/08071.pdf
https://arxiv.org/abs/2407.01851
Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Leveraging Large Language Models' remarkable proficiency in text-based tasks, recent works on Multi-modal LLMs (MLLMs) extend them to other modalities like vision and audio. However, the progress in these directions has been mostly focused on tasks that on
arxiv.org
1. Introduction
LLM의 발전과 멀티모달 확장
최근 몇 년간 대규모 언어모델(LLM)의 비약적인 발전 -> 인간 수준의 이해력과 추론 능력 달성
instruction fine-tuning (지시 기반 미세조정) 패러다임 도입 -> 자연어 명령어를 이해하고 적합한 작업을 수행할 수 있게 됨
이러한 LLM를 다른 모달리티와 결합하는 흐름으로 확장됨 but 오디오는 상대적으로 덜 연구된 영역
기존 연구의 한계: Coarse-grained 중심
기존의 MLLM(멀티모달 LLM)의 한계:
1. 주로 coarse-grained (거시적인) task에 초점: 캡셔닝(audio captioning), 질의응답(audio QA) 등의 비교적 단순한 작업
2. fine-grained (세밀한) 오디오-비주얼 이해 부족: 일부 MLLM을 grounding에 사용하기 시작했지만 여전히 시각 정보에만 집중하거나 세밀한 이해 불가능
문제의식과 연구 목표
연구 목표: LLM을 통해 fine-grained (정밀한) 오디오-비주얼 이해를 달성하고자 함
but 어려운 이유:
1. 입출력 포맷의 다양성: 서로 다른 과제를 하나의 프레임워크에서 처리해야 함
2. 대규모 데이터셋의 부재: grounding 학습에 적합한 audio-visual 데이터셋
Meerkat 제안: 첫 Unified Audio-Visual LLM
기존 모델들(ex. BuboGPT, TimeChat)의 한계: coarse-grained task에 초점 & cross-modality fusion(교차 모달 결합)이 없어 fine-grained 이해 불가능
-> 이 문제들을 해결하기 위해 Meerkat 제안
Meerkat의 두 가지 핵심 모듈
1. Modality Alignment Module (모달리티 정렬 모듈): 최적 운송 기반으로 패치 레벨의 약한 감독 학습
2. Cross-modal Attention Consistency Module (교차 어텐션 일관성 모듈): cross-attention 히트맵을 강제하여 일관성 유지
=> 이 두 모듈이 오디오-비주얼 통합 표현 학습을 가능하게 함
MeerkatBench와 AVFIT Dataset
Meerkat 모델을 학습시키고 검증하기 위해 MeerkatBench와 AVFIT Dataset을 함께 제시
MeerkatBench: 5가지의 오디오-비주얼 과제를 통합한 벤치마크
1) Audio-referred Image Grounding
2) Image-guided Audio Temporal Localization
3) Audio-Visual Fact Checking
4) Audio-Visual Question Answering
5) Audio-Visual Captioning
AVFIT Dataset
약 3백만(3M)개의 instruction-tuning 샘플로 구성된 대규모 데이터셋
fine-grained 오디오-비주얼 이해를 학습하도록 설계됨
주요 기여
1. 세밀한 공간적/시간적 gounding이 가능한 최초의 오디오-비주얼 LLM인 Meerkat 제시
2. 5가지 오디오-비주얼 학습 과제를 통합한 MeerkatBench와 대규모 AVFIT dataset 제시
3. 모든 벤치마크 과제에서 State-of-the-Art 성능 달성
2. Related Works
Multi-modal Large Language Models
LLM의 지시 수행 (instruction-following) 능력 -> LLM을 다른 모달리티로 확장하려는 흐름
LLM을 멀티모달로 확장하기 위한 두 가지 주요 접근 방식
1. Latent Alignment 방식
LLM은 고정하고 학습된 비주얼 인코더를 통해 latent alignment (잠재 공간 정렬) 학습
ex. MiniGPT-4, X-LLM, Video-ChatGPT
2. Cross-attention 삽입 방식
LLM 내부에 cross-attention 층을 추가하여 멀티모달 정보를 처리할 수 있도록
ex. Otter, LLaMA-Adapter
기존 연구의 한계: 대부분 시각 정보에 집중, coarse-grained tasks 위주
이 연구의 목표: LLM에 강한 오디오-비주얼 이해 능력 부여
Fine-grained Multi-modal Understanding
범용 MLLM의 발전 -> 비전-언어(vision-language) 혹은 비디오 이해(video understanding) 과제를 통합적으로 다룰 수 있게 됨
+ MLLM에 region-based grounding tasks(영역 기반 그라운딩 과제)를 통합시키려는 시도도 나타남
기존 연구의 한계: 단일 모달리티(보통 비전-언어)에 제한됨
이 연구의 목표: 오디오-비주얼 과제 통합 프레임워크 제시
3. Methodology

3.1. Multi-modal Feature Extraction
Image Encoder (이미지 특징 추출)
하나의 배치에 k 장의 이미지

- H: 이미지 높이
- W: 이미지 너비
- C: 채널 수 (RBG이면 3)
사용 모델: CLIP ViT-B/16
이미지 한 장은 토큰 (패치) 단위로 쪼개진 다음에 패치 임베딩으로 표현됨

- z_I: 이미지 임베딩
- S_I: 이미지 토큰 (패치) 개수
- D_I: 각 토큰의 임베딩 차원
Audio Encoder (오디오 특징 추출)
하나의 배치에 k 개의 오디오

- F: 스펙트럼 성분 개수
- T: 시간 프레임 개수
사용 모델: CLAP Audio Transformer
오디오 한 개는 토큰 (시간 구간) 단위로 쪼개진 다음에 패치 임베딩으로 표현됨

- z_A: 오디오 임베딩
- S_A: 오디오 토큰 (시간 구간) 수
- D_A: 각 토큰의 임베딩 차원
LLM
사용 모델: Llama 2-Chat (7B)
텍스트 명령은 LLM의 토크나이저를 통해 토큰 시퀀스로 변환된 다음에 임베딩으로 변환됨
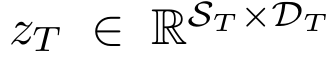
- S_T: 텍스트 토큰 수
- D_T: 각 토큰의 임베딩 차원
각 모달리티 임베딩의 차원이 다름 -> 이를 맞춰추기 위해 추가적인 선형 변환 층 (linear projection layer)
이미지, 오디오 임베딩이 LLM에 맞춰짐 -> LLM이 Meerkat의 통합 인터페이스 역할을 함
3.2. Audio-Visual Feature Alignment
오디오와 비주얼 간의 의미적 정렬을 학습하기 위해 두 수준의 정렬을 사용
1) Audio-Visual Optimal Transport Alignment Module (AVOpT)
-> 패치 수준의 약한 감독 정렬 (weak supervision, global-level)
설계 동기: fine-grained supervision (세밀한 감독) 학습을 바로 학습시키는 대신, 먼저 weak supervision (약한 감독) 학습을 먼저 시키는 것이 효과적이라는 것이 입증됨
배경 연구 1: siamese network에서 EMD(Earth Mover Distance)와 OT(Optimal Transport; 최적 운송) 기반 알고리즘이 사용됨 -> 쿼리 이미지와 서포트 이미지 강 패치 수준의 정렬 수행
배경 연구 2: 비전-언어 모델에서도 OT 기반 방법이 확장되어 사용됨 -> 이미지의 패치와 문장의 단어 간 정렬 수행
배경 연구 3: 한 모달리티를 선형 투영(linear projection)을 통해 다른 모달리티 공간으로 옮겨서 정렬 수행 (OT 대신 선형 투영 사용)
문제 인식: CLIP(이미지 인코더)와 CLAP(오디오 인코더)는 각각 따로 학습됨 -> 두 임베딩이 서로 다른 의미 공간(semantic space)에 있음
-> 패치 레벨의 정렬이 이미지와 오디오 사이의 의미적 일관성(semantic consistency)을 향상시킴 (대조 학습보다 더 나음)
패치 임베딩 z_I, z_A를 확률 분포로 표현 (각 모달리티의 임베딩 집합을 질량이 분포된 확률 공간으로 보는 것)
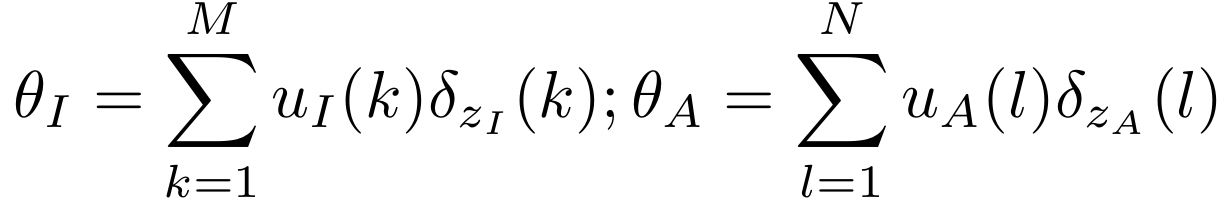
목표: 이미지 패치 분포와 오디오 패치 분포를 맞추는 최소 비용 분포를 찾는 것
=> 확률 분포 간 Wasserstein Distance (WD = EMD) 구하기
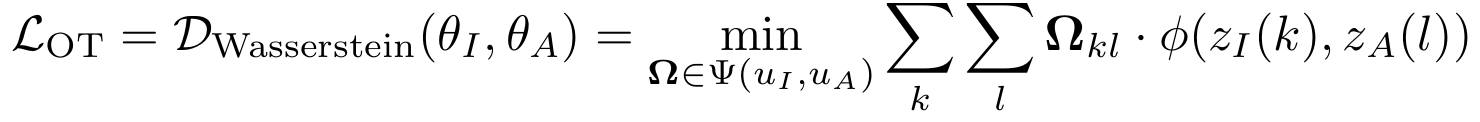
요약: AVOpT는 이미지와 오디오의 패치 임베딩을 확률 분포로 보고, Earth Mover’s Distance 기반 Optimal Transport 를 이용해 두 분포 간 최소 운송 비용을 계산함으로써 패치 수준에서 의미적으로 일관된 약한 정렬(weak alignment)을 수행하는 모듈
2) Audio-Visual Attention Consistency Enforcement Module (AVACE)
-> 객체 단위의 강한 감독 정렬 (strong supervision, local-level)
설계 동기: AVOpT는 패치 수준의 약한 정렬을 제공하지만, 아직 오디오와 비주얼 간 구체적인 객체 수준(region-level) 인식은 부족함 (상대 모달리티의 세부 정보를 충분히 반영하지 X)
상호정보를 주입하기 위해 Cross-Attention 구조 사용
문제: 주의 분산 (inconsistency) -> 단순 cross-attention만 사용하면 오디오의 attention이 이미지 전체로 퍼짐
이유: CLAP은 문장-오디오 쌍으로 학습되었기 때문
-> cross-modality attention map 사용 (ground-truth bounding box를 이용해 마스크 M 정의)

목표: 객체 내부(마스크=1) → attention을 최대화 / 객체 외부(마스크=0) → attention을 최소화
3.3. Overall training objective


4. MeerkatBench: A Unified Benchmark Suite for Fine-grained Audio-Visual Understanding
4.1. Task Overview
Fine-grained tasks
1) Audio-Referred Image Grounding (ARIG): 주어진 오디오에 대응하는 영상 내 객체의 위치를 찾는 과제
2) Image-Guided Audio Temporal Localization (IGATL): 주어진 이미지에 대응하는 오디오의 시간 구간을 찾는 과제
3) Audio-Visual Fact Checking (AVFC): 주어진 오디오와 영상의 내용이 서로 일치하는지 판단하는 과제
Coarse-grained tasks
4) Audio-Visual Question Answering (AVQA): 주어진 오디오+영상 정보를 종합해 자연어 질문에 답하는 과제
5) Audio-Visual Captioning (AVCap): 주어진 오디오+영상을 종합해 문장 설명(caption)을 생성하는 과제
4.2. AVFIT-3M: Audio Visual Finegrained Instruction Tuning Dataset
AVFIT-3M: MeerkatBench의 학습 기반이 되는 대규모 학습 데이터셋
- 총 샘플 수: 약 3백만 (3M) 멀티모달 instruction–response 쌍
- 형태: 대화식 instruction–response 형식
- 구성 방법: 2 step
Step 1. Adaptation of Public Datasets (공개 데이터셋 재구성)
1) Direct Collection (직접 수집) <- VGG-SS, AVSBench, Flickr-SoundNet, LLP, AVQA, MUSIC-AVQA, VALOR
2) Semi-automated Pairing (반자동 구성) <- Openimages, PASCAL, AudioSet, VGG-Sound (사전에 만들어둔 lookup table을 보고 같은 클래스로 매칭시키는 것)
Step 2. GPT-Assisted Instruction Generation (GPT 기반 지시문 생성)
기존의 instruction tuning 데이터셋들은 주로 coarse-grained task에 초점 -> fine-grained (공간/시간 단위) 오디오-비주얼 이해에는 적합하지 않음. -> 그래서 세 가지 방법으로 이 문제 개선
1) 오디오와 연결될 객체의 공간 좌표를 포함 -> region-level 이해 강화
2) 오디오 이벤트의 시간 구간을 입출력에 포함 -> temporal reasoning 학습 유도
3) GPT-3.5로 각 태스크 별 예시를 다양하게 생성 + GPT-4로 재프롬프트하여 품질 향상
=> 이 세 과정으로 여러 개의 지시 포맷을 생성 (not specific instruction): 지시 포맷은 special token을 포함함
학습 시점에 이 스페셜 토큰들이 실제 데이터로 대체되는 것.
5. Experiments and Results
5.1. Baselines
Meerkat의 독창성: Meerkat은 오디오-비주얼 공간적/시간적 그라운딩을 모두 통합한 최초의 MLLM임
-> 따라서 task 별로 가장 유사한 baseline을 선정하여 공정하게 비교함
task1) ARIG: BuboGPT’s
task2) IGATL: TimeChat
task3) AVFC: X-InstructBLIP
task4) AVQA: Macaw-LLM
task5) AVCap: PandaGPT, VideoLlama
5.2. Main Results
1) Audio-Referred Image Grounding (ARIG)
주어진 오디오에 대응하는 영상 내 객체의 위치를 찾는 과제

2) Image-Guided Audio Temporal Localization (IGATL)
주어진 이미지에 대응하는 오디오의 시간 구간을 찾는 과제
성능이 좋은 이유: AVOpT, AVACE 두 가지 모듈을 사용하기 때문

3) Audio-Visual Fact Checking (AVFC)
주어진 오디오와 영상의 내용이 서로 일치하는지 판단하는 과제
학습에 GT 박스나 시간 구간이 직접적으로 사용되지 않음에도 fine-grained task인 이유: global한 장면이 아니라 객체, 시간 구간 등 세부적 정보에 집중해야 하기 때문
model의 response: 이진 답변 (True/False)
type1) 이미지의 박스 안의 개체가 오디오의 소리를 내는지 판단 (공간 중심)
type2) 이미지 속 객체가 해당 시간 구간의 오디오와 관련이 있는지 판단 (시간 중심)
type3) 이미지의 박스 안의 객체가 특정 시간 구간의 오디오의 소리와 일치하는지 판단 (공간+시간 통합)
type4) 오디오가 이미지 속 장면과 관련이 있는지 판단 -> 의미적 매칭 (global, 전반적)

4) Audio-Visual Question Answering (AVQA)
주어진 오디오+영상 정보를 종합해 자연어 질문에 답하는 과제
5) Audio-Visual Captioning (AVCap)
주어진 오디오+영상을 종합해 문장 설명(caption)을 생성하는 과제

Meerkat이 coarse-grained 과제에도 잘 확장되는 이유: 정밀한 오디오-비주얼 의미 이해를 학습했기 때문
=> Meerkat은 fine-grained task와 coarse-grained task 모두를 처리할 수 있는 범용 멀티모달 모델 (MLLM)
5.3. Ablation Study
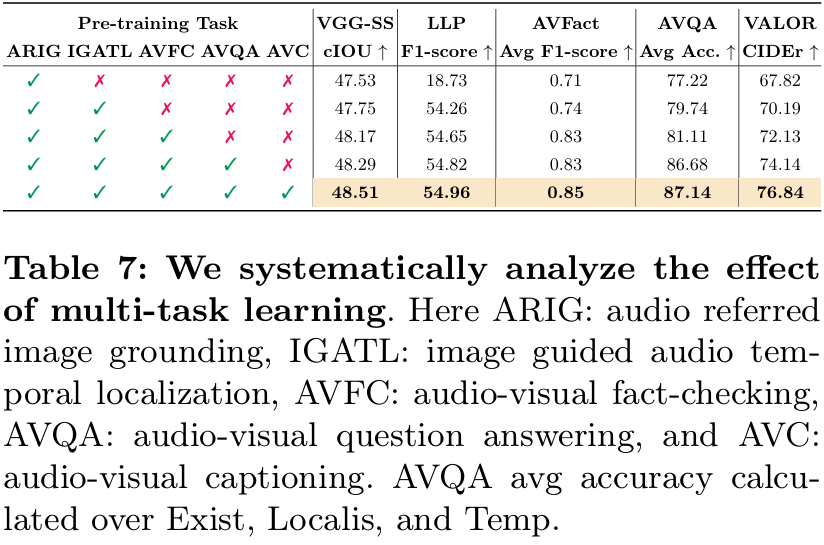
Study1) 단일 과제 학습(single-task) vs. 통합 다중 과제 학습(multi-task) 비교
multi-task 학습이 single-task 학습보다 전반적으로 더 좋은 성능
fine-grained task로 학습한 모델은 coarse-grained task에서도 매우 좋은 성능을 보임
반대로, coarse-grained task 학습을 추가한다고 fine-grained task 성능이 크게 향상되지는 않음
-> 즉, fine-grained task 학습이 훨씬 중요한 역할을 함
Study2) 전체 LLM 파라미터 미세조정(full fine-tuning) vs. LoRA 기반 경량 미세조정(LoRA fine-tuning) 비교
cf. LoRA(Low-Rank Adaptation): LLM 전체 파라미터를 직접 업데이트하지 않고, 작은 low-rank 행렬을 추가 학습함으로써 메모리/시간 효율적으로 fine-tuning하는 방법
LoRA rank 값 r = {4, 16, 32}으로 실험
-> r=4,16는 성능 낮고 r=32는 full fine-tuning보다도 약간 더 성능이 좋음
LoRA가 fine-tuning 시 기존 LLM의 일반화 성질을 보존하면서 필요한 영역만 정교하게 조정한 것

5.4. Qualitative Analysis
정성적 비교로 Meerkat의 강점을 시각적으로 보여줌

6. Conclusions and Future Works
Meerkat은 오디오-비주얼 입력을 동시에 처리하고 공간적+시간적 세부 정보까지 이해할 수 있는 강력한 multi-modal LLM이다.
AVOpT 모듈 + AVACE 모듈 -> 시청각 정보에 대한 강력한 조합적 이해력(compositional understanding) -> 다양하고 복잡한 멀티모달 과제 처리 가능
훈련용 데이터셋 AVFIT, 평가용 벤치마크 MeerkatBench -> 앞으로의 AV-LLM 연구에 표준으로 사용될 수 있는 기반을 마련
다양한 downstream task에 대해서 일관되게 SOTA 성능 달성
향후 연구 방향
1) LLM-guided AV Segmentation: LLM 기반의 보다 정밀한 시청각 불할로 발전시킬 예정
2) Video 확장 및 시간적 과제: 영상을 직접 입력으로 받을 수 있게 하여 video temporal grounding, video summarization 등의 과제 가능하도록
3) 대규모 Video-centric 데이터 구축: 대규모 비디오 중심 멀티모달 데이터셋과 복잡한 추론(Reasoning) 평가 벤치마크
'AI' 카테고리의 다른 글
| Image, Text, Audio 멀티모달 데이터셋 조사 (0) | 2025.07.30 |
|---|---|
| [논문 리뷰] ImageBind: One Embedding Space To Bind Them All (0) | 2025.07.24 |
| [논문 리뷰] AudioCLIP: Extending CLIP to Image, Text and Audio (2) | 2025.07.23 |
| MDETR 모델 주요 코드 분석 (0) | 2025.07.18 |
| [논문 리뷰] FedMSplit: Correlation-Adaptive Federated Multi-Task Learning across Multimodal Split Networks (2) | 2025.07.11 |

