
정화 코딩
Image, Text, Audio 멀티모달 데이터셋 조사 본문
Text ↔ Image Datasets
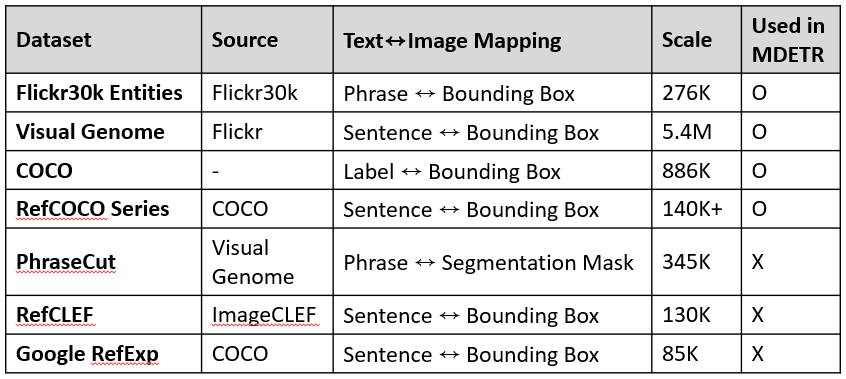
Flickr30k Entities
- 기존 Flickr30k(이미지+문장 캡션)에 명사구 별 bounding box 어노테이션 추가된 데이터셋
- 이미지 + 각 이미지에 대해 5개의 문장(캡션) + 각 문장 내 명사구(phrase) ↔ bounding box 정보 ⇒ 전처리 없이 사용 가능
- 이미지 31,783개, 이미지 당 객체 8.7개, 총 박스 276K개
- https://arxiv.org/abs/1505.04870
- https://github.com/BryanPlummer/flickr30k_entities
- https://bryanplummer.com/Flickr30kEntities/
Visual Genome (VG)
- Flickr 기반 이미지 + 각 이미지에 대해 여러 개의 region-level 캡션(일부 영역에 대한 자유문장 설명)과 bounding box
- 즉, “문장 내 개별 명사구 ↔ box 매핑”이 아니라 “문장 전체 ↔ box” 매핑
- 이미지 108K개, region 캡션/박스 5422K개
- https://arxiv.org/abs/1602.07332
- https://homes.cs.washington.edu/~ranjay/visualgenome/index.html
COCO
- 이미지 + 각 이미지에 대해 5개의 문장(캡션) +각 객체 클래스(레이블)별 bounding box 정보
- 이미지 123K개(총 328K인데 일반적인 object detection 학습에서는 train/val 포함 약 123K 사용), 이미지당 객체 7.7개, 총 박스 886K개
- https://arxiv.org/abs/1405.0312
- https://cocodataset.org/#home
RefCOCO / RefCOCO+ / RefCOCOg
- COCO 이미지 기반
- 이미지 + 각 이미지에 대해 여러 개의 referring expression(지시 표현) ↔ 단일 객체 bounding box 쌍
- 즉, 문장 전체가 하나의 객체를 가리킴 (문장 내 명사구 여러 개 X)
- 이미지 19K+개, 캡션/박스 140K+개
- https://github.com/lichengunc/refer
PhraseCut
- Visual Genome (VG) 기반
- VG의 요소들을 조합해 자연어 명사구 (phrase) 생성 + phrase 별로 사람이 직접 마킹한 segmentation mask
- segmentation mask를 box로 변환 가능
- 이미지 77K개, phrase/mask 345K개
- https://arxiv.org/abs/2008.01187
- https://github.com/ChenyunWu/PhraseCutDataset
RefCLEF (ReferIt: The ReferItGame)
- ImageCLEF 이미지 기반
- 문장 전체 ↔ 단일 box 쌍
- 이미지 19,894개, 표현 130K개
- https://aclanthology.org/D14-1086/
- https://github.com/lichengunc/refer
- https://www.cs.rice.edu/~vo9/referit/
Google RefExp (Google Referring Expressions Dataset)
- COCO (2014) 이미지 기반
- 문장 전체 ↔ 단일 box 쌍
- 이미지 26,711개, 표현 85,474개
- https://github.com/mjhucla/Google_Refexp_toolbox
- https://arxiv.org/abs/1511.02283
Audio ↔ Image Datasets
VGG-SS (VGG Sound Source Benchmark)
- 기존 VGG-Sound(오디오+클래스 레이블)에서 정적 프레임을 추출해서 객체를 bounding box로 어노테이션한 데이터셋
- VGG-Sound에서 추출한 오디오 + 특정 프레임에서 해당 사운드의 원인 객체의 bounding box
- 비디오 클립 5K개, 프레임 8K개, 박스 수천개
- https://arxiv.org/abs/2104.02691
- https://github.com/hche11/VGGSound
- http://www.robots.ox.ac.uk/~vgg/research/lvs/
AVSBench (Audio-Visual Segmentation Benchmark)
- 오디오 + 이미지에서 사운드의 원인이 되는 객체의 segmentation mask
- segmentation mask → bounding box로 변환 가능
- 비디오 클립 수천개, 박스 수만개
- https://arxiv.org/abs/2207.05042
- https://github.com/OpenNLPLab/AVSBench
- https://opennlplab.github.io/AVSBench/
OpenImages-AudioSet Grounding (Meerkat benchmark)
- AudioSet에서 추출한 오디오 + Open Images 데이터셋에서 추출한 정적 이미지 + 해당 사운드를 발생시키는 객체의 bounding box 정보
- 무관한 데이터셋인 AudioSet와 Open Images를 수동 또는 자동 매칭으로 연결한 것
- 이미지 1.9M개, 박스 15.4M개
- https://arxiv.org/html/2407.01851v2
- https://github.com/schowdhury671/meerkat

Text ↔ Audio Datasets
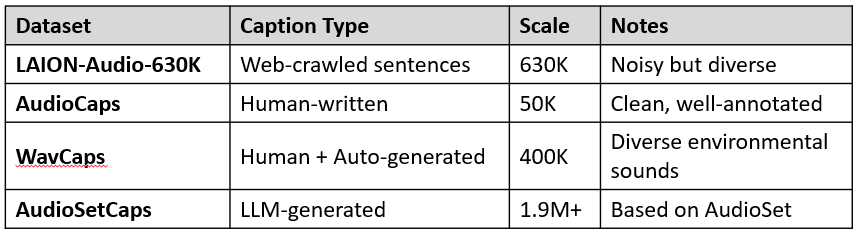
LAION-Audio-630K
- 여러 웹사이트에서 수집된 오디오와 해당 텍스트 설명
- 캡션은 자연어 문장 형태, 다소 노이즈 있음
- 오디오–텍스트 쌍 633,526개
- https://arxiv.org/html/2211.06687v4
- https://github.com/LAION-AI/audio-dataset
AudioCaps
- AudioSet에서 추출한 오디오 클립에 대해 사람이 직접 작성한 자연어 문장 캡션
- 캡션 품질 우수
- 오디오 50,000개
- https://aclanthology.org/N19-1011/
- https://github.com/cdjkim/audiocaps
- https://audiocaps.github.io/
WavCaps
- 다양한 환경음, 자연음에 대해 사람이 작성한 캡션 또는 자동 생성된 텍스트 캡션 포함
- 오디오–텍스트 쌍 400,000개
- https://arxiv.org/abs/2303.17395
- https://github.com/XinhaoMei/WavCaps
AudioSetCaps
- AudioSet 오디오 클립에 대해 LLM을 활용해 생성한 자연어 캡션
- 오디오-텍스트 쌍 190만개
- https://arxiv.org/abs/2411.18953
- https://github.com/JishengBai/AudioSetCaps
'AI' 카테고리의 다른 글
| [논문 리뷰] Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time (0) | 2025.11.18 |
|---|---|
| [논문 리뷰] ImageBind: One Embedding Space To Bind Them All (0) | 2025.07.24 |
| [논문 리뷰] AudioCLIP: Extending CLIP to Image, Text and Audio (2) | 2025.07.23 |
| MDETR 모델 주요 코드 분석 (0) | 2025.07.18 |
| [논문 리뷰] FedMSplit: Correlation-Adaptive Federated Multi-Task Learning across Multimodal Split Networks (2) | 2025.07.11 |


