
정화 코딩
[논문 리뷰] ImageBind: One Embedding Space To Bind Them All 본문
https://arxiv.org/abs/2305.05665
ImageBind: One Embedding Space To Bind Them All
We present ImageBind, an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. We show that all combinations of paired data are not necessary to train such a joint embedding, and only image
arxiv.org
1. Introduction
아이디어: 이미지의 결합(binding) 능력 -> 다양한 센서와 정렬(align) 가능
기존 연구: 주로 이중 모달리티 쌍만 학습 -> 학습에 사용된 쌍 외에는 활용이 어려움
But, 모든 모달리티가 동시에 포함된 대규모 데이터셋 부족 (=근본적인 한계)
=> ImageBind 제안: 이미지와 다른 모달리티의 쌍만 활용해도, 모든 모달리티 간 공통 임베딩 공간 학습 가능 ()
여러 모달리티들이 이미지라는 중간 매개체를 통해 간접적으로 서로 정렬됨 -> 명시적 쌍 없이도 여러 모달리티가 자연스럽게 연결됨
활용 가능한 작업: cross-modal retrieval (크로스 모달 검색), combining embeddings via arithmetic (모달리티 임베딩 간 연산), detecting audio sources in images (이미지에서 오디오 소스 감지), generating images given audio input (오디오로부터 이미지 생성) 등
2. Related Work
1. Language Image Pre-training (언어-이미지 사전학습)
이미지와 텍스트(단어/문장)를 함께 학습 -> 제로샷 인식 및 텍스트 기반 이미지 검색에 효과적임
대표적인 연구들:
- CLIP, ALIGN, Florence: 대규모 이미지-텍스트 쌍을 수집해 대조 학습(contrastive learning)으로 공통 임베딩 공간 학습
- CoCa: 대조 학습에 캡셔닝 목적을 결합해 성능 향상
- Flamingo: 이미지-텍스트가 섞인 입력을 다룰 수 있고 few-shot 성능 우수
- LiT: 이미지 인코더를 고정하고 텍스트 인코더만 학습하는 방식이 효과적
기존 연구의 한계점: 대부분 이미지와 텍스트만을 대상으로 함
=> ImageBind: 다양한 모달리티로 확장
2. Multi-Modal Learning (멀티모달 학습)
기존 연구들: 다양한 모달리티 간 공동 임베딩을 supervised 또는 self-supervise 방식으로 시도함
- CLIP 기반 확장 모델: 영상 표현을 텍스트와 매칭해 semantic representation 강화
- Nagrani et al.: 캡션, 오디오, 영상이 약하게 연결된 데이터셋으로 멀티모달 학습
- AudioCLIP: CLIP에 오디오를 추가해 오디오 제로샷 분류 가능
=> ImageBind의 차별점: 이미지를 중간 매개체로 활용해 다양한 모달리티 간 자연스러운 연결 유도 -> 명시적 쌍 없이도 학습 가능
3. Feature Alignment (특징 정렬 & 전이학습)
CLIP: 시각 표현력이 강해서 다른 모델의 교사 모델(teacher)로 자주 사용됨. CLIP 임베딩 공간은 제로샷 객체 탐지, 분할, 3D 인식 등의 작업에 활용 가능
자연어 번역(NMT): 여러 언어를 하나의 잠재 공간(latent space)에 정렬하면, 직접적인 짝이 없는 언어쌍도 번역 가능
3. Method
목표: 하나의 공통 임베딩 공간에서 다양한 모달리티를 이미지를 중심으로 정렬 (이미지를 중심 허브처럼 사용하여, 다른 모달리티들이 직접 연결되지 않아도 간접적으로 연결되도록)
3.1. Preliminaries
1. Aligning specific pairs of modalities (모달리티 쌍 정렬)
대조 학습(Contrastive Learning): 양의 샘플(관련된 쌍)과 음의 샘플(무관한 쌍)을 비교하면서 임베딩 공간을 학습하는 방식
한계점: 학습된 임베딩은 해당 쌍에만 특화 -> 다른 모달리티 쌍에 직접 사용 불가능
2. Zero-shot image classification using text prompts (텍스트 기반 제로샷 이미지 분류)
CLIP은 이미지와 텍스트를 정렬한 뒤, 텍스트 프롬프트만으로도 이미지 분류 가능
한계점: 텍스트와의 직접적인 정렬이 필요
=> ImageBind의 차별점: 텍스트와 직접 정렬된 적 없는 모달리티에도 제로샷 분류 가능
3.2. Binding modalities with images
ImageBind: (I, M) 형태의 모달리티 쌍 사용 (I: 이미지, M: 다른 모달리티)
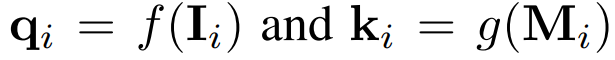
- 이미지 I_i는 q_i로 임베딩
- 모달리티 M_i는 k_i로 임베딩
- f, g: 딥러닝 기반 인코더
InfoNCE 기반 대조 손실

Emergent alignment of unseen pairs of modalities
학습한 적 없는 쌍에 대해서도 자연스럽게 정렬됨 (이미지가 중간 매개체 역할을 해서)
효과: 한 번의 훈련으로 다양한 모달리티 간 제로샷 검색/분류 가능
3.3. Implementation Details
전체 구조 개요
모든 모달리티에 대해 별도의 인코더 사용. 인코더는 Transformer 기반
임베딩 출력은 고정된 차원(d)으로 변환되고 (by Linear Projection Head) 정규화된 후, InfoNCE Loss로 학습
가능한 경우, 사전학습 모델(CLIP, OpenCLIP)을 활용해 초기화
이미지 (Image)
ViT 인코더 사용
사전학습된 CLIP 인코더를 그대로 활용 가능
비디오 (Video)
이미지와 동일한 ViT 인코더 사용
2초 길이의 비디오에서 2개의 프레임을 추출하여 인코더의 입력으로 사용
인코더에 Temporal Inflation 적용 (patch projection layer를 시간축으로 확장 -> 2D 구조를 3D 구조로 변환): 시간 정보를 처리할 수 있는 비디오 전용 ViT 인코더가 됨
오디오 (Audio)
2초 길이의 오디오(샘플링 주파수 16kHz)를 스펙트로그램으로 변환 (by 128 mel-spectrogram bins)
-> 스펙트로그램은 2D이므로 이미지처럼 다룰 수 있음
열화상 (Thermal) / 깊이 (Depth)
둘 다 1채널 이미지로 처리 → ViT 사용
깊이 정보는 Disparity Map으로 변환
IMU (Inertial Measurement Unit)
5초 클립 -> 약 2000개 타임스텝
전처리: 1D convolution으로 시계열 데이터 축소
텍스트 (Text)
CLIP의 텍스트 인코더 구조 사용
자연어 문장을 토큰화하여 Transformer로 처리
4. Experiments
6가지 모달리티
- 이미지 / 비디오 (ViT 기반)
- 텍스트 (CLIP / OpenCLIP 기반)
- 오디오 (mel-spectrogram 변환)
- 깊이(Depth) (Disparity map 사용)
- 열화상(Thermal) (1채널 이미지)
- IMU 센서 (가속도계 + 자이로스코프 시계열 데이터)
모달리티 쌍 데이터셋
- (비디오, 오디오): AudioSet
- (이미지, 깊이): SUN RGB-D
- (이미지, 열화상): LLVIP
- (비디오, IMU): Ego4D
대규모 이미지-텍스트 쌍 (웹 기반)
웹에서 수집한 수십억 개의 (image, text) 쌍 활용 (OpenCLIP 기반)
사용된 사전학습 모델:
- Vision encoder: ViT-H, 630M 파라미터
- Text encoder: Transformer, 302M 파라미터
이 인코더들은 고정(frozen) 상태로 학습에 사용됨
모달리티 별 인코더
- 오디오 (mel-spectrogram 변환): ViT-B
- 깊이 / 열화상 (1채널 이미지로 처리): ViT-S
이미지/텍스트 인코더는 학습 중 고정(frozen) & 나머지 인코더들은 학습 도중 업데이트
Emergent Zero-Shot vs. 일반 Zero-Shot
일반 Zero-Shot: 해당 모달리티 쌍에 대해서
Emergent Zero-Shot: 본 적 없는 모달리티 쌍에서도 가능
4.1. Emergent zero-shot classification
실험 목적: 직접적으로 텍스트와 짝지어 학습한 적이 없는 모달리티에 대해, 텍스트 프롬프트 기반 제로샷 분류가 가능한지 평가.
결과: 모든 벤치마크에서 강력한 emergent 제로샷 성능 달성. 일부 작업에서는 전문 supervised 모델보다 더 나은 성능 달성.
해석: 이미지-텍스트 정렬에서 얻은 텍스트 감독 정보(text supervision)를 이미지와 정렬된 다른 모달리티로 자연스럽게 전이(transfer)시킴.
4.2. Comparison to prior work
Zero-shot text to audio retrieval and classification
기존 방식:
- AudioCLIP: (오디오, 텍스트) 쌍을 supervision으로 학습
- AVFIC: (오디오, 텍스트) 쌍을 자동으로 수집해서 학습
IMAGEBIND 방식: 오디오와 텍스트 쌍을 단 한 번도 학습하지 않음. only (오디오, 이미지), (텍스트, 이미지) 쌍만 사용
결과: Clotho 데이터셋 기준 성능 크게 향상, ESC 기준 AudioCLIP에 근접한 성능
해석: 이미지와 각각 정렬된 텍스트/오디오가, 서로도 정렬된 것처럼 작동함 (emergent alignment)
Text to audio and video retrieval
텍스트 설명이 주어졌을 때 해당 오디오 혹은 비디오를 검색하는 작업
텍스트 -> 오디오, 텍스트 -> 비디오에서도 좋은 성능. 텍스트 -> 멀티모달(오디오+비디오 조합)에서는 추가 성능 향상.
4.3. Few-shot classification
실험 목적: 소량의 학습 샘플(few-shot)만 주어졌을 때, 얼마나 잘 분류할 수 있는지 평가
비교 대상:
- AudioMAE (Self-supervised)
- AudioMAE (Supervised)
4.4. Analysis and Applications
Multimodal embedding space arithmetic (멀티모달 임베딩 공간의 조합성)
서로 다른 모달리티(예: 이미지 + 오디오)의 임베딩을 더해서 새로운 의미 조합을 생성
의의: 별도 재학습 없이도 기존 모델에 활용 가능. 기존 CLIP 임베딩을 사용하던 비전 모델에 오디오 임베딩으로 교체하여 즉시 활용 가능.
Upgrading text-based detectors to audio-based (텍스트 기반 객체 탐지기 -> 오디오 기반 탐지기로 전환)
Detic: 텍스트 프롬프트를 기반으로 객체를 탐지하는 모델
Detic 모델에서 CLIP 기반 클래스 임베딩을 ImageBind의 오디오 임베딩으로 교체
의의: 별도의 훈련 없이도 해당 오디오에 대응하는 객체를 이미지에서 탐지하고 세분화(segmentation)까지 수행 가능
Upgrading text-based diffusion models to audio-based (텍스트 기반 생성 모델 -> 오디오 기반 생성 모델로 전환)
DALLE-2: 텍스트 설명을 기반으로 이미지를 생성하는 diffusion 기반 생성 모델
DALLE-2 모델에서 텍스트 임베딩을 IMAGEBIND의 오디오 임베딩으로 교체
의의: 소리 기반 이미지 생성, 음성 입력 기반 상상화 생성 등 새로운 응용 가능
'AI' 카테고리의 다른 글
| [논문 리뷰] Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time (0) | 2025.11.18 |
|---|---|
| Image, Text, Audio 멀티모달 데이터셋 조사 (0) | 2025.07.30 |
| [논문 리뷰] AudioCLIP: Extending CLIP to Image, Text and Audio (2) | 2025.07.23 |
| MDETR 모델 주요 코드 분석 (0) | 2025.07.18 |
| [논문 리뷰] FedMSplit: Correlation-Adaptive Federated Multi-Task Learning across Multimodal Split Networks (2) | 2025.07.11 |

