
Notice
Recent Posts
Link
정화 코딩
[ML] 감정 기반 오디오 변환 모델 만들기 본문
가상환경 생성
conda create -n emotionTTS python=3.10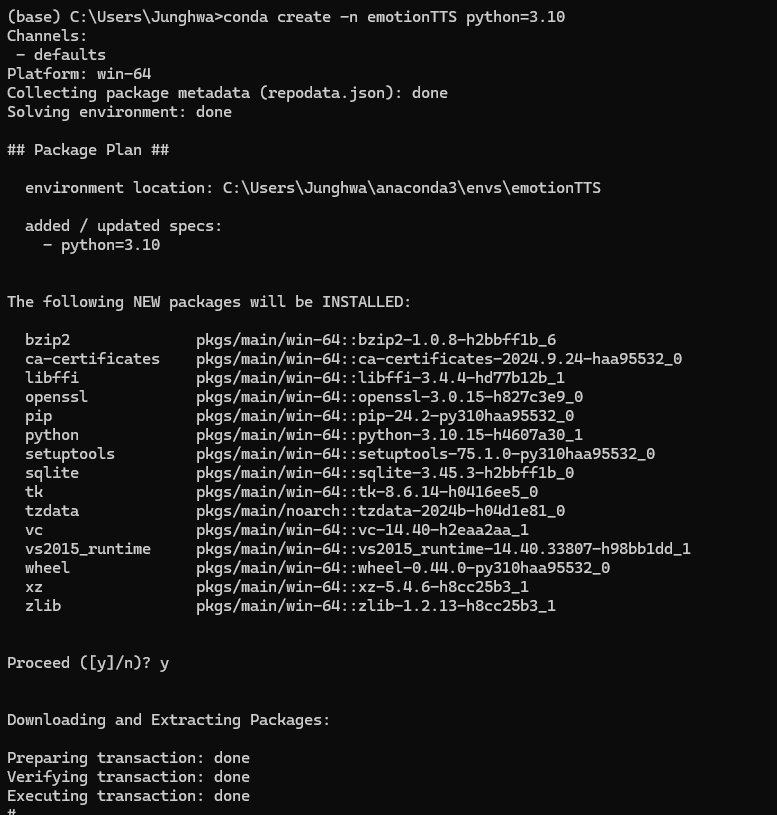
필요한 라이브러리 설치
conda activate emotionTTS
pip install librosa torch torchvision torchaudio matplotlib pandas
사진에는 몇개 빠졌지만 위에 적은 것들 전부 받아야 한다.
프로젝트 구조

모델 관련 코드
# emotionTTS.py
import torch
import torch.nn as nn
class EmotionTTS(nn.Module):
def __init__(self, emotion_embedding_dim, input_dim, output_dim):
"""
감정 정보를 반영하여 Mel Spectrum을 생성하는 TTS 모델.
Parameters:
- emotion_embedding_dim (int): 감정 임베딩 벡터의 차원.
- input_dim (int): 입력 Mel Spectrum의 차원.
- output_dim (int): 출력 Mel Spectrum의 차원.
"""
super(EmotionTTS, self).__init__()
# 감정 임베딩 레이어 (6개의 감정 레이블)
self.emotion_embedding = nn.Embedding(6, emotion_embedding_dim)
# Encoder: Mel Spectrum과 감정 임베딩을 처리
self.encoder = nn.Conv1d(input_dim + emotion_embedding_dim, 512, kernel_size=3, stride=1, padding=1)
# Decoder: 감정 반영 Mel Spectrum 생성
self.decoder = nn.Conv1d(512, output_dim, kernel_size=3, stride=1, padding=1)
# 활성화 함수
self.relu = nn.ReLU()
def forward(self, x, emotion_label):
"""
Forward pass
Parameters:
- x (Tensor): 입력 Mel Spectrum, shape = (batch_size, input_dim, seq_len)
- emotion_label (Tensor): 감정 레이블, shape = (batch_size,)
Returns:
- Tensor: 출력 Mel Spectrum, shape = (batch_size, output_dim, seq_len)
"""
# 감정 레이블을 임베딩 벡터로 변환
emotion_embedding = self.emotion_embedding(emotion_label).unsqueeze(2) # (batch_size, embedding_dim, 1)
# Mel Spectrum에 감정 임베딩 추가
x = torch.cat((x, emotion_embedding.expand(-1, -1, x.size(2))), dim=1) # (batch_size, input_dim + embedding_dim, seq_len)
# Encoder: 입력 Mel Spectrum 처리
encoded = self.relu(self.encoder(x))
# Decoder: 감정 반영 Mel Spectrum 생성
decoded = self.decoder(encoded)
return decoded# train.py
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from preprocess import MelSpectrogramDataset, collate_fn # CSV 기반 데이터셋 사용
from emotionTTS import EmotionTTS # 모델 임포트
# CSV 파일 경로 설정
CSV_PATH = "dataset/emotion_melpath_dataset.csv"
# CSV 구조: [Mel Spectrum .npy 파일 경로, 감정 레이블]
# 데이터셋 및 DataLoader 준비
if not os.path.exists(CSV_PATH):
raise FileNotFoundError(f"CSV file '{CSV_PATH}' does not exist. Please check the path.")
dataset = MelSpectrogramDataset(csv_file=CSV_PATH) # 데이터셋 클래스
train_loader = DataLoader(dataset, batch_size=32, shuffle=True, collate_fn=collate_fn) # DataLoader
# 모델 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
input_channels = 128 # Mel Spectrum의 채널 수
emotion_embedding_dim = 32
output_dim = 128 # 출력 Mel Spectrum 크기
model = EmotionTTS(emotion_embedding_dim=emotion_embedding_dim, input_dim=input_channels, output_dim=output_dim)
model.to(device)
# 손실 함수 및 최적화 함수
criterion = nn.MSELoss() # Mel Spectrum의 차이를 최소화
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 학습률을 낮게 설정하여 안정적 학습
# 훈련 루프
epochs = 20
for epoch in range(epochs):
model.train()
total_train_loss = 0
for mel_spectrograms, labels, masks in train_loader: # masks 포함
mel_spectrograms, labels, masks = mel_spectrograms.to(device), labels.to(device), masks.to(device)
optimizer.zero_grad()
# 모델에 입력
outputs = model(mel_spectrograms, labels) # 감정 레이블과 함께 모델에 전달
# 출력 크기를 입력 크기에 맞게 조정
mel_spectrograms_resized = F.interpolate(mel_spectrograms, size=outputs.size(2), mode='linear', align_corners=False)
# 손실 계산 (마스크를 적용하여 패딩된 부분 무시)
loss = criterion(outputs, mel_spectrograms_resized)
masked_loss = (loss * masks).sum() / masks.sum() # 마스크 적용
total_train_loss += masked_loss.item()
# 역전파 및 최적화
masked_loss.backward()
optimizer.step()
# 에포크별 손실 출력
print(f"Epoch [{epoch + 1}/{epochs}], Training Loss: {total_train_loss / len(train_loader)}")
# 모델 저장
MODEL_PATH = "models/emotion_tts_model.pth"
os.makedirs(os.path.dirname(MODEL_PATH), exist_ok=True) # 경로 생성
torch.save(model.state_dict(), MODEL_PATH)
print(f"Model saved to {MODEL_PATH}")# inference.py
import torch
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
from train import EmotionTTS
from preprocess import AudioDataset
def transform_audio(input_file, target_emotion, model_path='models/emotion_tts_model.pth'):
# 모델 로드
model = EmotionTTS()
model.load_state_dict(torch.load(model_path))
model.eval()
# 오디오 파일 로드
y, sr = librosa.load(input_file, sr=22050)
mel = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
mel_db = librosa.power_to_db(mel, ref=np.max)
# 모델을 통한 Mel Spectrum 변형
mel_tensor = torch.tensor(mel_db).unsqueeze(0).unsqueeze(0).float()
with torch.no_grad():
emotion_vector = model(mel_tensor)
# 여기서 emotion_vector를 통해 변형된 Mel Spectrum 생성 (추가 논리 필요)
# 변형된 Mel Spectrum을 오디오로 변환
transformed_audio = librosa.feature.inverse.mel_to_audio(mel_db, sr=sr)
librosa.output.write_wav('outputs/transformed.wav', transformed_audio, sr)
print(f"Transformed audio saved at outputs/transformed.wav")
# 예시 실행
transform_audio(input_file='data/neutral/example.wav', target_emotion='happy')# utils.py
import librosa
def load_audio(file_path, sr=22050):
y, _ = librosa.load(file_path, sr=sr)
return y
def save_audio(file_path, y, sr=22050):
librosa.output.write_wav(file_path, y, sr)# preprocess.py
import librosa
import numpy as np
import os
import pandas as pd
import torch
def generate_mel_spectrograms(csv_path, output_dir):
os.makedirs(output_dir, exist_ok=True) # 저장 디렉토리 생성
# CSV 파일 읽기
df = pd.read_csv(csv_path)
for _, row in df.iterrows():
wav_path = row['file_path']
output_path = os.path.join(output_dir, os.path.basename(wav_path).replace(".wav", ".npy"))
try:
y, sr = librosa.load(wav_path, sr=22050)
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)
np.save(output_path, mel_spec_db)
print(f"Saved: {output_path}")
except Exception as e:
print(f"Error processing {wav_path}: {e}")
class MelSpectrogramDataset(torch.utils.data.Dataset):
def __init__(self, csv_file):
self.data = pd.read_csv(csv_file)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
mel_path = self.data.iloc[idx, 0]
mel_spectrogram = np.load(mel_path)
mel_spectrogram = torch.tensor(mel_spectrogram, dtype=torch.float32)
label = int(self.data.iloc[idx, 1])
label = torch.tensor(label, dtype=torch.long)
mask = torch.ones(mel_spectrogram.shape[1], dtype=torch.float32)
return mel_spectrogram, label, mask
def collate_fn(batch):
mel_spectrograms, labels, masks = zip(*batch)
max_len = max(mel.shape[1] for mel in mel_spectrograms)
mel_spectrograms_padded = torch.zeros(len(batch), mel_spectrograms[0].shape[0], max_len)
masks_padded = torch.zeros(len(batch), max_len)
for i, mel in enumerate(mel_spectrograms):
mel_spectrograms_padded[i, :, :mel.shape[1]] = mel
masks_padded[i, :mel.shape[1]] = 1
return mel_spectrograms_padded, torch.stack(labels), masks_padded
# 실행 코드 추가
if __name__ == "__main__":
csv_path = "datasets/emotion_melpath_dataset.csv"
output_dir = "datasets/melspecs/"
generate_mel_spectrograms(csv_path, output_dir)# process_emotion_datasets.py
import os
import pandas as pd
# 감정 레이블 매핑
emotion_mapping = {
"neutral": 0,
"happy": 1,
"sad": 2,
"angry": 3,
"fear": 4,
"disgust": 5
}
# 데이터셋 경로 설정
ravdess_path = "datasets/RAVDESS/"
tess_path = "datasets/TESS/"
cremad_path = "datasets/CREMA-D/"
# 결과 저장 리스트
result = []
# RAVDESS 처리
for root, _, files in os.walk(ravdess_path):
for file in files:
if file.endswith(".wav"):
# 파일 이름에서 감정 번호 추출 (예: "03-01-01-01-01-01-01.wav")
parts = file.split("-")
if len(parts) > 2:
emotion_code = parts[2]
if emotion_code == "01":
result.append((os.path.join(root, file), emotion_mapping["neutral"]))
elif emotion_code == "03":
result.append((os.path.join(root, file), emotion_mapping["happy"]))
elif emotion_code == "04":
result.append((os.path.join(root, file), emotion_mapping["sad"]))
elif emotion_code == "05":
result.append((os.path.join(root, file), emotion_mapping["angry"]))
elif emotion_code == "06":
result.append((os.path.join(root, file), emotion_mapping["fear"]))
elif emotion_code == "07":
result.append((os.path.join(root, file), emotion_mapping["disgust"]))
# TESS 처리
for root, _, files in os.walk(tess_path):
for file in files:
if file.endswith(".wav"):
# 파일 경로에서 감정 추출 (예: "OAF_angry/OAF_back_angry.wav")
emotion = root.split("/")[-1].split("_")[-1].lower()
if emotion in emotion_mapping:
result.append((os.path.join(root, file), emotion_mapping[emotion]))
# CREMA-D 처리
for root, _, files in os.walk(cremad_path):
for file in files:
if file.endswith(".wav"):
# 파일 이름에서 감정 추출 (예: "1001_DFA_ANG_XX.wav")
parts = file.split("_")
if len(parts) > 2:
emotion = parts[2].lower()
if emotion == "neu":
result.append((os.path.join(root, file), emotion_mapping["neutral"]))
elif emotion == "hap":
result.append((os.path.join(root, file), emotion_mapping["happy"]))
elif emotion == "sad":
result.append((os.path.join(root, file), emotion_mapping["sad"]))
elif emotion == "ang":
result.append((os.path.join(root, file), emotion_mapping["angry"]))
elif emotion == "fea":
result.append((os.path.join(root, file), emotion_mapping["fear"]))
elif emotion == "dis":
result.append((os.path.join(root, file), emotion_mapping["disgust"]))
# 결과를 DataFrame으로 변환
df = pd.DataFrame(result, columns=["file_path", "emotion_label"])
# CSV로 저장
output_csv_path = "datasets/emotion_melpath_dataset.csv"
df.to_csv(output_csv_path, index=False)
print(f"CSV 파일이 '{output_csv_path}'에 저장되었습니다.")# update_csv.py
import pandas as pd
import os
# 원본 CSV 파일 경로
input_csv_path = "datasets/emotion_melpath_dataset.csv"
# 수정된 CSV 파일 저장 경로
output_csv_path = "datasets/emotion_melpath_dataset_updated.csv"
# Mel Spectrum 저장 디렉토리
mel_dir = "datasets/melspecs/"
# CSV 파일 읽기
df = pd.read_csv(input_csv_path)
# 파일 경로를 .npy로 변환
def update_to_npy_path(wav_path):
# .wav 파일 경로를 .npy 파일 경로로 변환
npy_file_name = os.path.basename(wav_path).replace(".wav", ".npy")
return os.path.join(mel_dir, npy_file_name)
# DataFrame의 file_path 필드 업데이트
df['file_path'] = df['file_path'].apply(update_to_npy_path)
# 업데이트된 CSV 저장
df.to_csv(output_csv_path, index=False)
print(f"Updated CSV saved to: {output_csv_path}")데이터셋 준비하기
RAVDESS Emotional speech audio 다운받기
CREMA-D 다운받기
Toronto emotional speech set (TESS) 다운받기
datasets/RAVDESS/
├── Actor_01/
│ ├── 03-01-01-01-01-01-01.wav
│ ├── ...
└── Actor_24/
├── 03-01-06-02-02-01-24.wav
└── ...datasets/TESS/
├── OAF_angry/
│ ├── OAF_back_angry.wav
│ ├── ...
└── YAF_sad/
├── YAF_beg_sad.wav
└── ...datasets/CREMA-D/
├── 1001_DFA_ANG_XX.wav
├── 1002_IEO_HAP_HI.wav
└── ...다운받은 데이터 셋들을 datasets라는 폴더 아래에 위와 같이 위치시킨다.
python src/process_emotion_datasets.py
process_emotion_datasets.py 파일을 실행시킨다.

그 결과로 이렇게 emotion_melpath_dataset.csv 파일이 생성된 것을 확인할 수 있다. 이렇게 하나의 csv파일로 모아서 감정 라벨링을 하는 이유는 각 데이터 셋마다 파일명 중 어떤 부분이 감정을 나타내는지 다르기 때문이다.
python src/preprocess.py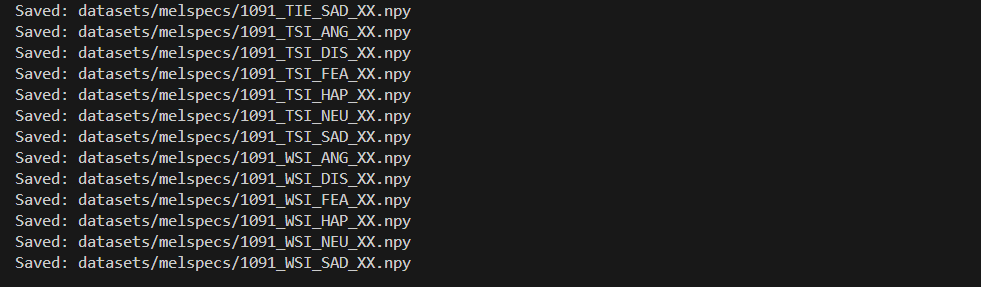
preprocess.py 파일을 실행시켜서 .wav 파일을 Mel Spectrum .npy 파일로 변환해준다.

그 결과 이렇게 melspecs라는 새로운 폴더가 만들어지고 그 안에 .npy 파일들이 생긴 것을 확인할 수 있다.
python src/update_csv.py
update_csv.py 파일을 실행시켜 emotion_melpath_dataset.csv에서 .wav 파일 경로를 .npy 파일 경로로 업데이트하여 emotion_melpath_dataset_updated.csv라는 새로운 파일로 저장해준다.
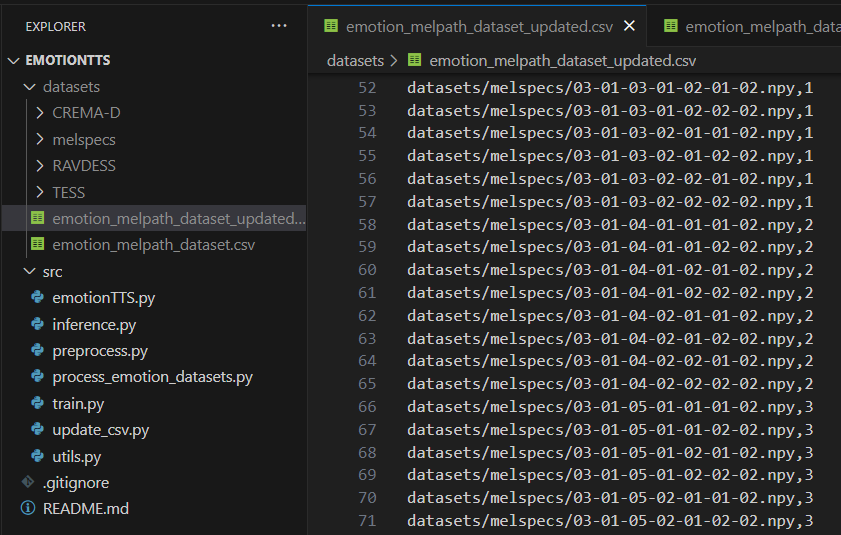
이렇게 기존의 .wav 파일 경로가 .npy 파일 경로로 수정되어 저장되었다.
모델 학습시키기
python src/train.py
모델 테스트하기
python src/test.py
'Machine Learnig' 카테고리의 다른 글
| [ML] Simple Two Hidden Layer Deep Learning, Convolutional Neural Network (CNN) (1) | 2024.11.20 |
|---|---|
| [ML] F5-TTS 모델 fine-tuning하기 (2) | 2024.11.18 |
| [ML] F5-TTS 모델 pre-train하기 (0) | 2024.11.17 |
| [ML] F5-TTS model 파인튜닝을 위한 데이터 모으기 (4) | 2024.11.16 |
| [ML] Spam Classification via Naïve Bayes (1) | 2024.10.16 |
'Machine Learnig' Related Articles
more




Comments