
Notice
Recent Posts
Link
정화 코딩
[ML] Simple Two Hidden Layer Deep Learning, Convolutional Neural Network (CNN) 본문
Machine Learnig
[ML] Simple Two Hidden Layer Deep Learning, Convolutional Neural Network (CNN)
jungh150c 2024. 11. 20. 02:15Simple Two Hidden Layer Deep Learning
import tensorflow as tf
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, accuracy_score
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# MNIST 데이터셋 로드
(X_train_full, y_train_full), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# 데이터 전처리: 픽셀 값을 0~1 사이로 스케일링
X_train_full = X_train_full.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0
# 데이터 평탄화 (28x28 이미지를 784차원의 벡터로 변환)
X_train = X_train_full.reshape(-1, 28 * 28)
X_test = X_test.reshape(-1, 28 * 28)
# 데이터 분할: training 데이터와 testing 데이터로 나누기
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train_full, test_size=0.2, random_state=42)
# 모델 생성: 두 개의 hidden layer가 있는 neural network
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)), # 첫 번째 hidden layer
tf.keras.layers.Dense(64, activation='relu'), # 두 번째 hidden layer
tf.keras.layers.Dense(10, activation='softmax') # 출력층 (10개의 클래스)
])
# 모델 컴파일
model.compile(
optimizer='adam', # 옵티마이저
loss='sparse_categorical_crossentropy', # 손실 함수
metrics=['accuracy'] # 평가 지표 (정확도)
)
# 모델 학습
history = model.fit(
X_train, y_train,
epochs=20, # 에포크 수
validation_data=(X_val, y_val),
batch_size=32 # 배치 크기
)
# 모델 평가
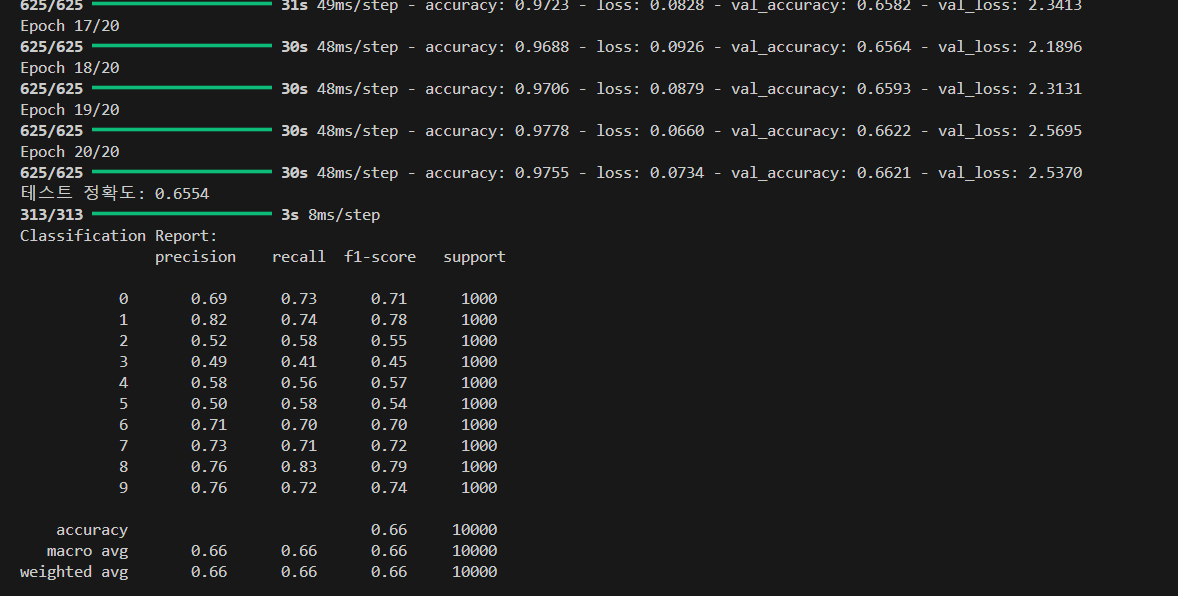
test_loss, test_accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f"테스트 정확도: {test_accuracy:.4f}")
# 혼동 행렬 계산 및 시각화
y_pred = np.argmax(model.predict(X_test), axis=-1)
conf_matrix = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=range(10))
disp.plot(cmap='viridis')
plt.title('Confusion Matrix')
plt.show()
# 학습 곡선 시각화
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Training and Validation Accuracy')
plt.show()

이렇게 Import "tensorflow" could not be resolved라는 오류가 나면


vscode 우측 하단에 있는 python의 버전을 anaconda 버전으로 바꿔준다.

노란줄 사라짐!



혼동 행렬의 구조
행(True Label): 실제 레이블을 나타냄.
열(Predicted Label): 모델이 예측한 레이블을 나타냄.
혼동 행렬 해석
대각선 값 (정확한 예측): 대각선((i, i))에 위치한 값은 정확히 예측된 샘플 수를 나타냄.
비대각선 값 (오류 예측): 대각선 이외의 셀은 잘못된 예측을 나타냄.
결과 분석
모델의 전반적인 성능: 대각선 값이 클수록, 즉 대각선이 뚜렷하게 강조될수록 모델의 정확도가 높음.
Convolutional Neural Network (CNN)



[참고]
handson-ml3/10_neural_nets_with_keras.ipynb at main · ageron/handson-ml3 · GitHub
handson-ml3/11_training_deep_neural_networks.ipynb at main · ageron/handson-ml3 · GitHub
handson-ml3/14_deep_computer_vision_with_cnns.ipynb at main · ageron/handson-ml3 · GitHub
'Machine Learnig' 카테고리의 다른 글
| [ML] 감정 기반 오디오 변환 모델 만들기 (1) | 2024.11.22 |
|---|---|
| [ML] F5-TTS 모델 fine-tuning하기 (2) | 2024.11.18 |
| [ML] F5-TTS 모델 pre-train하기 (0) | 2024.11.17 |
| [ML] F5-TTS model 파인튜닝을 위한 데이터 모으기 (4) | 2024.11.16 |
| [ML] Spam Classification via Naïve Bayes (1) | 2024.10.16 |
'Machine Learnig' Related Articles
more




Comments