
정화 코딩
[ML] F5-TTS 모델 pre-train하기 본문
아나콘다 설치하기
Anaconda | The Operating System for AI
Democratize AI innovation with the world’s most trusted open ecosystem for data science and AI development.
www.anaconda.com

우측 상단에 Free Download를 클릭한다.

메일 인증을 완료하면 다운받을 수 있는 페이지로 이동한다.

일단 계속 Next 누르면 된다.

위와 같이 옵션을 선택해주고 Install 해주었다.
F5-TTS 설치
https://github.com/SWivid/F5-TTS
GitHub - SWivid/F5-TTS: Official code for "F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching"
Official code for "F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching" - SWivid/F5-TTS
github.com
fork 후 clone 받는다. 그 후 해당 링크에 들어가면 보이는 리드미에서 Installation 부분을 참고하여 진행한다.
# Create a python 3.10 conda env (you could also use virtualenv)
conda create -n f5-tts python=3.10
conda activate f5-tts
# Install pytorch with your CUDA version, e.g.
pip install torch==2.3.0+cu118 torchaudio==2.3.0+cu118 --extra-index-url https://download.pytorch.org/whl/cu118

Python 3.10 환경을 위한 f5-tts Conda 가상환경을 생성하고 활성화한 후, CUDA 버전에 맞춰 PyTorch와 Torchaudio를 설치한다.
pip install -e .
현재 디렉토리의 패키지를 개발 모드로 설치한다.
F5-TTS 학습시키기 (pre-train)
https://github.com/SWivid/F5-TTS/tree/main/src/f5_tts/train
F5-TTS/src/f5_tts/train at main · SWivid/F5-TTS
Official code for "F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching" - SWivid/F5-TTS
github.com
training 부분의 리드미를 참고하여 진행한다. 특히 2. Create custom dataset with metadata.csv 부분에 있는 #57 here에 자세히 나와있다.
원하는 데이터 준비하기
yt-dlp -x --audio-format wav https://www.youtube.com/watch?v=SlgKIJaoXd8
유튜브에서 wav 파일로 다운로드한다.
자세한 방법은 내가 저번에 쓴 글 참고! https://jungh150c.tistory.com/193
데이터를 학습시킬 수 있도록 가공하기
위와 같이 그냥 맨 바깥에 유튜브에서 다운받은 Fernanda_Ramirez.wav 파일을 옮겨주고, 이 파일을 학습시킬 수 있는 형태로 잘라주기 위한 whisper_test.py 파일을 만들어준다.
# whisper_test.py
import whisper
import torch
import soundfile as sf
import torchaudio
import os
import csv
# 사용할 장치 설정
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"[INFO] Using device: {device}")
# Whisper 모델 로드 및 장치로 이동
print("[INFO] Loading Whisper model...")
model = whisper.load_model("large").to(device)
audio_path = "Fernanda_Ramirez.wav"
output_dir = "wavs"
os.makedirs(output_dir, exist_ok=True)
print(f"[INFO] Model loaded. Preparing to process {audio_path}")
# 오디오 데이터 로드 및 리샘플링
def load_audio_without_ffmpeg(audio_path):
print(f"[INFO] Loading audio file: {audio_path}")
waveform, sample_rate = sf.read(audio_path)
# 다중 채널인 경우, 한 채널로 변환 (예: 스테레오 -> 모노)
if waveform.ndim > 1:
waveform = waveform.mean(axis=1)
waveform = waveform.astype("float32") # float32로 변환
if sample_rate != 16000:
print(f"[INFO] Resampling audio from {sample_rate} Hz to 16000 Hz")
waveform = torch.from_numpy(waveform)
waveform = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=16000)(waveform).numpy()
print("[INFO] Audio loaded and resampled if necessary")
return waveform
# 오디오 파일을 로드하고 Whisper로 문장 단위 텍스트 추출
audio_data = load_audio_without_ffmpeg(audio_path)
audio_data_tensor = torch.tensor(audio_data) # torch 텐서로 변환
result = model.transcribe(audio_data_tensor, language="en")
# metadata.csv 파일 생성
with open("metadata.csv", "w", newline="", encoding="utf-8") as csv_file:
writer = csv.writer(csv_file, delimiter="|")
writer.writerow(["audio_file", "text"])
for i, segment in enumerate(result["segments"]):
start_time = int(segment["start"] * 16000) # 샘플 단위로 변환
end_time = int(segment["end"] * 16000)
text = segment["text"].strip()
# 문장 단위 오디오 세그먼트 추출 및 저장
segment_data = audio_data[start_time:end_time]
output_wav_path = os.path.join(output_dir, f"audio_segment_{i+1:04d}.wav")
torchaudio.save(output_wav_path, torch.tensor(segment_data).unsqueeze(0), 16000)
print(f"[INFO] Saved segment {i+1} as {output_wav_path}")
# metadata.csv 파일에 경로와 텍스트 기록
writer.writerow([f"wavs/audio_segment_{i+1:04d}.wav", text])
print(f"[INFO] Logged segment {i+1} text to metadata.csv")
print("[INFO] All segments processed. Files saved to 'wavs' and metadata.csv created.")whisper_test.py 파일의 내용은 위와 같다. 오디오 파일을 문장 단위로 잘라주는 역할을 한다.
참고로, model = whisper.load_model("large").to(device) 이 부분을 small, large, turbo 등으로 설정할 수 있고, 설정에 따라 분할 정확도와 속도(시간)가 달라진다.
pip install git+https://github.com/openai/whisper.git
whisper_test.py를 실행시키기 위해 whisper 라이브러리를 다운받는다.
python whisper_test.py
whisper_test.py를 실행시킨다.
40분짜리 오디오 기준 small은 1-2분 정도에 다 됐지만 large로 하니 1시간 좀 넘게 걸렸다.

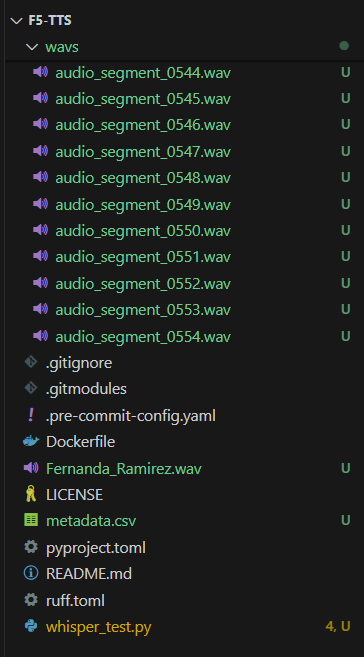
wav 폴더 안에 잘린 오디오 wav 파일들과 그 밖에 있는 metadata.csv 파일이 생성된 것을 확인할 수 있다.

이렇게 dataset이라는 폴더를 만들고 그 안에 아까 생성된 wav 폴더와 metadata.csv 파일을 넣어주면 된다.
dataset 준비하는 명령어 실행
python scripts/prepare_csv_wavs.py <path_to_your_dataset> <F5-TTS_repo_data_path>/<dataset_name>_char이런식으로 실행해주면 된다.
python src/f5_tts/train/datasets/prepare_csv_wavs.py my_dataset data/my_dataset_char나는 dataset 폴더를 F5-TTS 폴더, 즉 현재 명령어 실행 위치이기 때문에 이렇게 적었다.
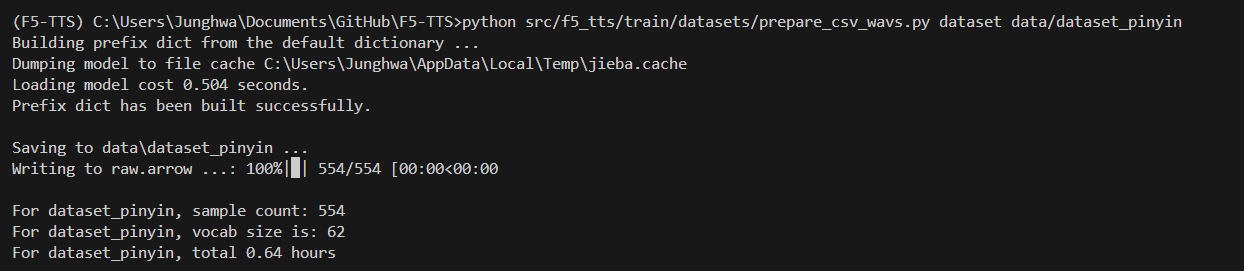
잘 실행되었다.
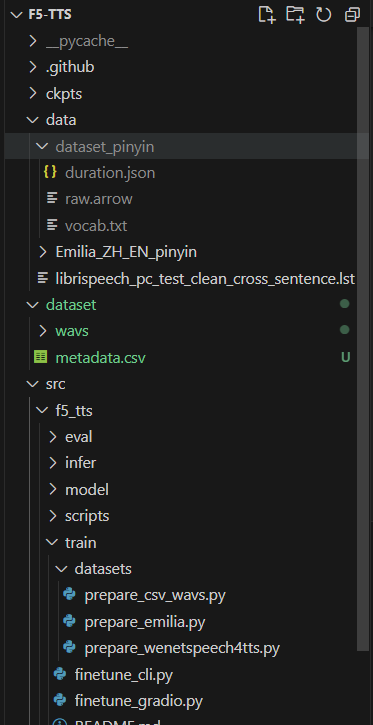
dataset_pinyin 폴더도 잘 생성되었다.
python src/f5_tts/train/train.py가상환경 활성화된 상태에서 train.py 스크립트를 실행시킨다.

에포크 1까지는 잘 되는 것 같다가 에포크 2로 넘어갈 때 쯤 오류가 났다.
(F5-TTS) C:\Users\Junghwa\Documents\GitHub\F5-TTS>python src/f5_tts/train/train.py
Using logger: None
Loading dataset ...
Download Vocos from huggingface charactr/vocos-mel-24khz
config.yaml: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 461/461 [00:00<?, ?B/s]
C:\Users\Junghwa\anaconda3\envs\F5-TTS\lib\site-packages\huggingface_hub\file_download.py:157: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\Junghwa\.cache\huggingface\hub\models--charactr--vocos-mel-24khz. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations.
To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to see activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development
warnings.warn(message)
pytorch_model.bin: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 54.4M/54.4M [00:00<00:00, 56.9MB/s]
Sorting with sampler... if slow, check whether dataset is provided with duration: 100%|████████████████████████████████████████████████████████████████████████████████████████| 554/554 [00:00<?, ?it/s]
Creating dynamic batches with 38400 audio frames per gpu: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 554/554 [00:00<?, ?it/s]
C:\Users\Junghwa\anaconda3\envs\F5-TTS\lib\site-packages\torch\utils\data\dataloader.py:558: UserWarning: This DataLoader will create 16 worker processes in total. Our suggested max number of worker in current system is 12 (`cpuset` is not taken into account), which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
l. Our suggested max number of worker in current system is 12 (`cpuset` is not taken into account), which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
necessary.
warnings.warn(_create_warning_msg(
warnings.warn(_create_warning_msg(
Traceback (most recent call last):
Traceback (most recent call last):
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\train\train.py", line 103, in <module>
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\train\train.py", line 103, in <module>
main()
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\train\train.py", line 96, in main
trainer.train(
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\train\train.py", line 96, in main
trainer.train(
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\model\trainer.py", line 257, in train
trainer.train(
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\model\trainer.py", line 257, in train
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\model\trainer.py", line 257, in train
start_step = self.load_checkpoint()
File "C:\Users\Junghwa\Documents\GitHub\F5-TTS\src\f5_tts\model\trainer.py", line 159, in load_checkpoint
latest_checkpoint = sorted(
IndexError: list index out of range오류 메세지는 위와 같고, gpt가 알려준대로 src/f5_tts/model/trainer.py 파일을 수정해보았다.
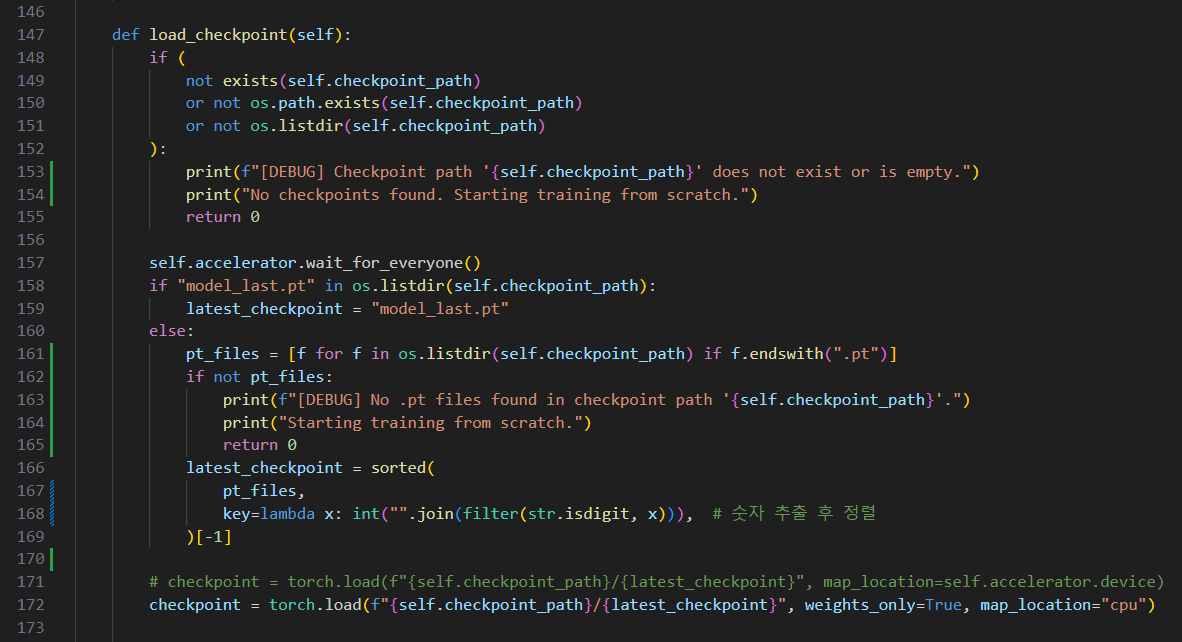
trainer.py 파일에 몇몇 디버깅 코드를 추가해주었고, pt_files이 존재하지 않는 경우도 처리하도록 했다.
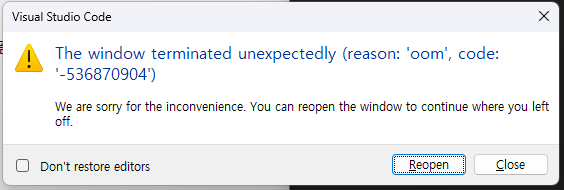
그래서 다시 실행시켜봤더니 이번엔 아예 vscode도 꺼지고 컴퓨터도 잠깐 먹통됨;; 난리..
여러번 시도해봤는데 그냥 말없이 꺼지기도 하고, os 페이지 부족하다고 터미널에 떴다가 꺼지기도 하고, 윈도우 에러 창 뜨고 꺼지기도 하고...
그래서 작업 관리자 열어서 확인해봤는데, 학습 안 시키고 있는데도 메모리 사용량이 많아서 한번 껐다 켜봤다. 메모리 사용량이 줄었길래 다시 도전!
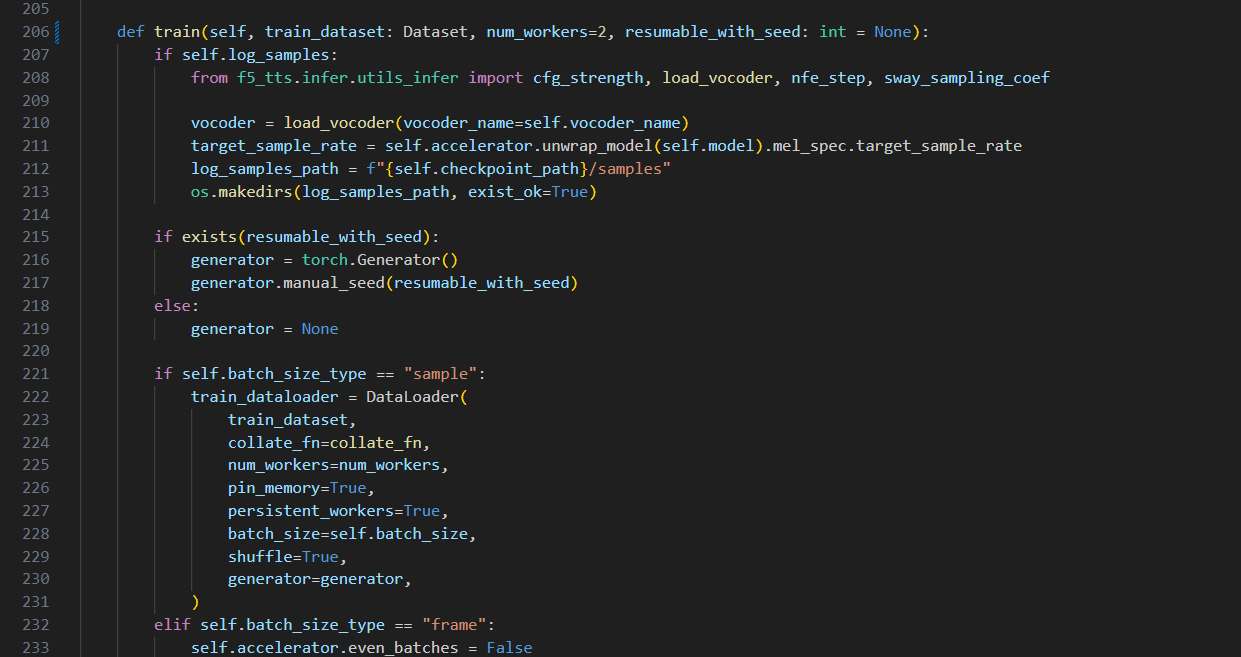
그리고 trainer.py 파일에서 데이터를 로드하는 부분, 즉 DataLoader를 호출하는 부분에서 num_workers의 기본값이 16이어서 너무 큰 것 같아 기본값을 2로 설정해주었다.

다행히 에포크 2까지 잘 되는 중이다.
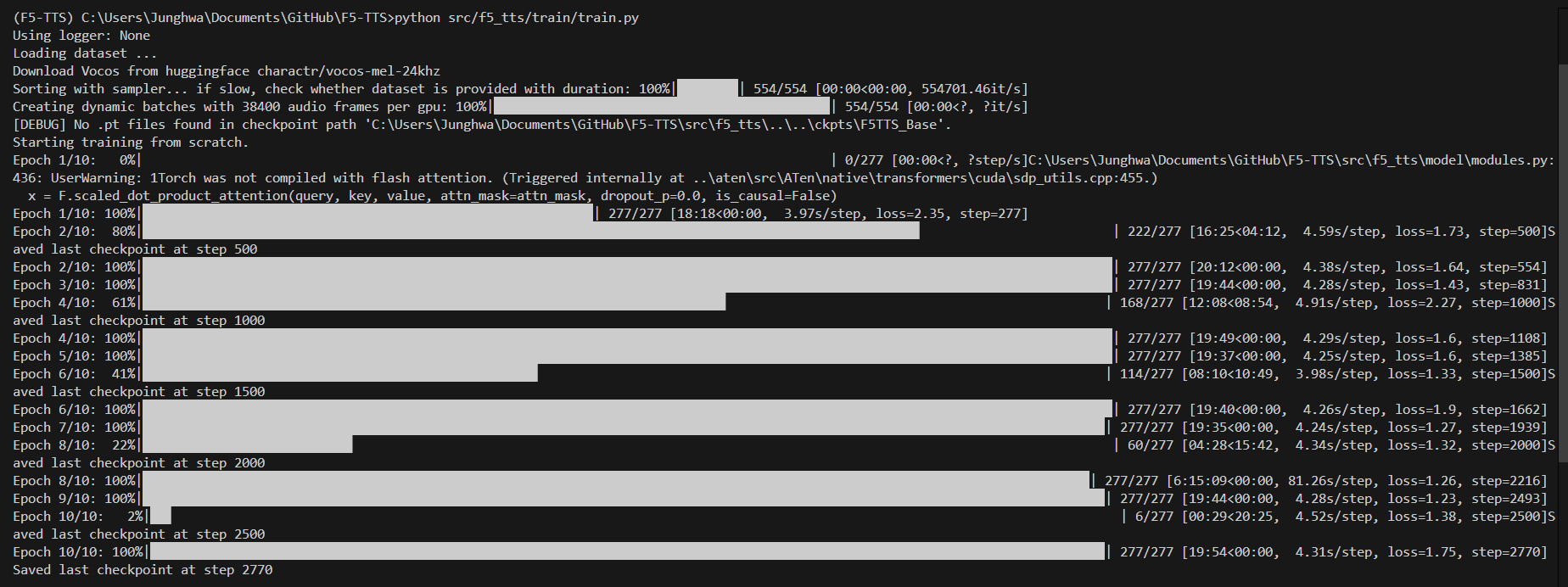
와 드디어 끝까지 성공!!
근데 생기는 샘플 오디오 파일을 확인해보니 사람 목소리도 전혀 안 들리고 기계음만 들린다... 뭐가 문제인지 찾아봐야할 것 같다.
'Machine Learnig' 카테고리의 다른 글
| [ML] 감정 기반 오디오 변환 모델 만들기 (1) | 2024.11.22 |
|---|---|
| [ML] Simple Two Hidden Layer Deep Learning, Convolutional Neural Network (CNN) (1) | 2024.11.20 |
| [ML] F5-TTS 모델 fine-tuning하기 (2) | 2024.11.18 |
| [ML] F5-TTS model 파인튜닝을 위한 데이터 모으기 (4) | 2024.11.16 |
| [ML] Spam Classification via Naïve Bayes (1) | 2024.10.16 |


