
정화 코딩
[논문 리뷰] MDETR - Modulated Detection for End-to-End Multi-Modal Understanding 본문
[논문 리뷰] MDETR - Modulated Detection for End-to-End Multi-Modal Understanding
jungh150c 2025. 7. 3. 11:52https://arxiv.org/abs/2104.12763
MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of obje
arxiv.org
0. Abstract
Multi-modal reasoning system (멀티모달 추론 시스템)
이미지, 텍스트, 음성 등 서로 다른 형태의 데이터를 함께 받아들여 그 관계를 이해하거나 추론하는 AI 시스템
-> 사전학습된 객체 탐지기(object detector)를 사용해 이미지를 처리함
| 예시 | 입력 | 출력 |
| VQA (Visual Question Answering) | 이미지 + 질문("사람이 들고 있는 물건은?") | 질문에 대한 올바른 정답 (“빨간 컵”) |
| Referring Expression Grounding | 이미지 + 문장(예: “파란 셔츠 입은 사람”) | 문장이 설명하는 객체의 박스 위치 (그 사람의 박스 위치) |
| Image Captioning | 이미지 | 이미지를 설명하는 문장 생성 (“고양이가 소파에 누워 있다”) |
| Image-Text Retrieval | 문장 → 이미지 찾기 or 이미지 → 문장 찾기 | 관련도 높은 쌍 찾기 |
기존 Multi-modal reasoning system의 한계
다운스트림 작업(downstream task)과 별도로 학습됨 + 고정된 어휘(fixed vocabulary)에 대해서 학습됨
-> 자유형식의 텍스트에 표현된 long-tail object(데이터에서 드물게 등장하는 객체)를 잘 포착하지 못함
해결책: MDETR (Modulated Detection for End-to-End Multi-Modal Understanding)
자유형식의 텍스트 쿼리(ex. 캡션, 질문)를 조건(condition)으로 삼아 객체를 탐지하는 end-to-end 모델
- 이미지-문장 쌍으로 사전학습(pre-training) 수행 (문장 내 문구와 이미지 내 객체 사이의 정확한 정렬(alignment) 정보가 있는 데이터셋 사용)
- 사전학습 후에 다양한 downstream 작업에서 fine-tuning하여 SOTA (state-of-the-art) 성능 달성
downstream 작업 예시
- Phrase Grounding: 문장에서 언급된 표현이 이미지에서 어디인지 찾기
- Referring Expression Comprehension/Segmentation: 지칭 표현이 가리키는 객체의 위치나 영역을 이해하고 분할
few-shot setting, long-tail category에서도 뛰어난 성능. VQA, GQA, CLEVR 등에도 적용 가능.
1. Introduction
기존 멀티모달 시스템의 한계
객체 탐지기(object detector)로 특정 객체를 인식한 후, 인식된 객체들만으로 텍스트와 정렬(alignment) 시도
- 전체 이미지가 아니라 일부 객체만 활용됨
- 고정된 카테고리와 특성 어휘만 인식 가능함
- 자유형식의 텍스트에서 새로운 단어 조합에 대응 어려움
MDETR
이미지와 텍스트를 함께 입력으로 받아서, 텍스트에 조건화된 객체 탐지(modulated detection)를 수행함
학습 시 텍스트 + 박스(box annotation)만 필요함 (라벨 클래스 없이)
- 자유형식 텍스트에서 미묘한 개념(nuanced concept)도 탐지 가능
- 새로운 단어 조합(ex. 핑크 코끼리)에도 잘 일반화됨
2. Method
2.1. Backgound
DETR (Detection Transformer): 최초의 Transformer 기반 end-to-end 객체 탐지 모델
- CNN: 2차원 이미지에서 feature를 추출하여 평탄화(flatten)된 feature vector를 출력함. (positional encoding까지 반영함.)
- Transformer Encoder: CNN에서 나온 feature들을 입력으로 받아, 전역적인 문맥 정보를 반영한 인코딩을 수행함.
- Transformer Decoder: N개의 object query들을 입력으로 받아, 인코딩된 이미지 정보와 cross-attention을 통해 각 query에 대한 output embedding을 예측함.
- Feed-Forward Network(FNN): 각각의 object query가 FNN을 거쳐 박스와 클래스 라벨("객체 없음 또는 배경"이라는 특수 클래스 포함)로 변환됨.
Hungarian Matching Loss를 통해 예측된 객체와 실체 객체 사이에 1:1 매칭을 찾아냄. -> 해당 쌍에 대해 Loss(L1+GloU)를 계산함.

2.2. MDETR
MDETR 구조
DETR 구조를 멀티모달 입력(텍스트+이미지)에 맞게 확장함.
- CNN: 2차원 이미지에서 feature를 추출하여 평탄화(flatten)된 feature vector를 출력함. (2D positional encoding까지 반영함.)
- RoBERTa: 사전학습된 Transformer 언어 모델. 텍스트로부터 feature를 추출하여 문장의 hidden vector를 출력함.
- 멀티모달 융합: 이미지와 텍스트 feature를 같은 embedding 공간으로 매핑하고, 그 둘을 concat함.
- Transformer Encoder(=cross encoder): concat된 vector를 입력으로 받아, 전역적인 문맥 정보를 반영한 인코딩을 수행함.
- Transformer Decoder: N개의 object query들을 입력으로 받아, 인코딩된 이미지 정보와 cross-attention을 통해 각 query에 대한 output embedding을 예측함.
- 출력: 각각의 object query에 대한 객체 박스를 예측함.

MDETR 학습 방법
텍스트와 객체 사이의 정렬 정보를 학습하기 위해, DETR에 2가지 추가적인 loss를 사용함.
1. Soft Token Prediction Loss (소프트 토큰 예측)
"고양이", "의자" 같은 클래스를 예측하는 것이 아니라, 예측된 박스가 어떤 토큰을 참조하는지를 예측함.
예측된 박스가 정답 박스와 매칭되면 -> 해당 객체를 나타내는 토큰 위치에 대한 확률 분포(uniform distribution)를 학습함.
즉, positional 정보를 통해 객체와 텍스트를 정렬하는 것!
cf. 여러 단어-하나의 객체, 하나의 단어-여러 객체 이런식으로 매칭될 수도 있음.
2. (Text-Query) Contrastive Alignment Loss (대조 정렬 손실)
시각적 객체의 embedding을 그에 대응하는 텍스트 토큰의 embedding과 가깝게 만듦. (무관한 토큰과는 멀게)
즉, 객체와 텍스트의 embedded representations(임베딩 표현)이 서로 가깝게 만들어주는 것!
=> box prediction loss (L1 & GIoU), soft-token prediction loss, contrastive alignment loss 세 손실을 더해서 최종 loss로 학습
3. Experiments
3.1. Pre-training Modulated Detection
목표: 텍스트에 따라 객체를 탐지하는(MDETR) 능력 기르기 (텍스트에서 언급된 객체들을 정확히 탐지할 수 있도록 학습)
Data combination (데이터 전처리&병합)
하나의 이미지에는 여러 문장(annotation)이 있을 수 있음 -> 이 문장들을 graph coloring 알고리즘을 사용해 병합
병합 조건: 1. 박스 간 GIoU ≤ 0.5 (서로 너무 겹치지 않도록), 2. 문장 길이 ≤ 250자 (텍스트가 너무 길지 않도록)
효과: 1. 데이터 효율성 증가, 2. soft token prediction loss의 학습 신호 강화
Model
Text Encoder: 사전학습된 RoBERTa-base
Visual Backbone: ResNet-101(ImageNet으로 사전학습된 전통적 CNN), EfficientNetB3/B5(Noisy-Student 방식으로 대규모 비지도 학습)
3.2. Downstream Tasks
1. Phrase Grounding
목표: 문장에서 특정 구절(phrase)에 해당하는 객체 위치(box) 찾기
평가 방식: 문장 내 여러 phrase마다 100개 박스 예측 후, 각 phrase에 해당하는 토큰 점수 기반으로 순위 매김
성과: 사전학습 없이도 기존 SOTA보다 Recall@1 기준 8.5% 향상, 사전학습 포함 시 12.1% 향상

2. Referring Expression Comprehension
목표: 문장이 지칭하는 객체 하나를 정확히 박스로 탐지
전략: 사전학습(MDETR) 단계에선 여러 객체를 예측하므로 이 작업에 맞게 5 에폭만 별도로 파인튜닝, ∅ (no object) 클래스 확률 P(∅)를 활용하여 1 - P(∅) 기준으로 박스 점수화
성과: 모든 RefCOCO 계열 데이터셋에서 기존 SOTA보다 현저히 더 좋은 성능

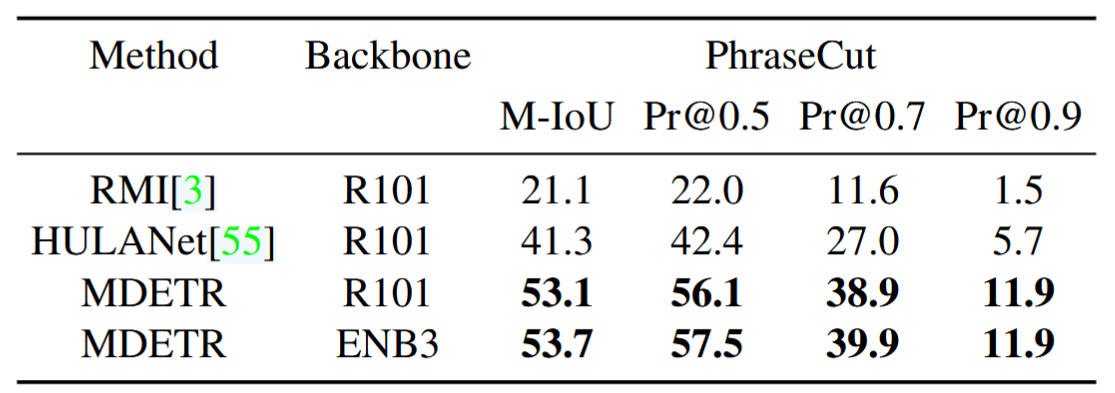
3. Referring Expression Segmentation
목표: 문장이 지칭하는 객체들 전체를 픽셀 단위로 분할(segmentation)
전략: 1. 박스 예측 fine-tuning (10 epochs), 2. segmentation head만 학습 (35 epochs)
성과: long-tail 객체도 깨끗하게 분할 가능, 다양한 표현에 대응 가능
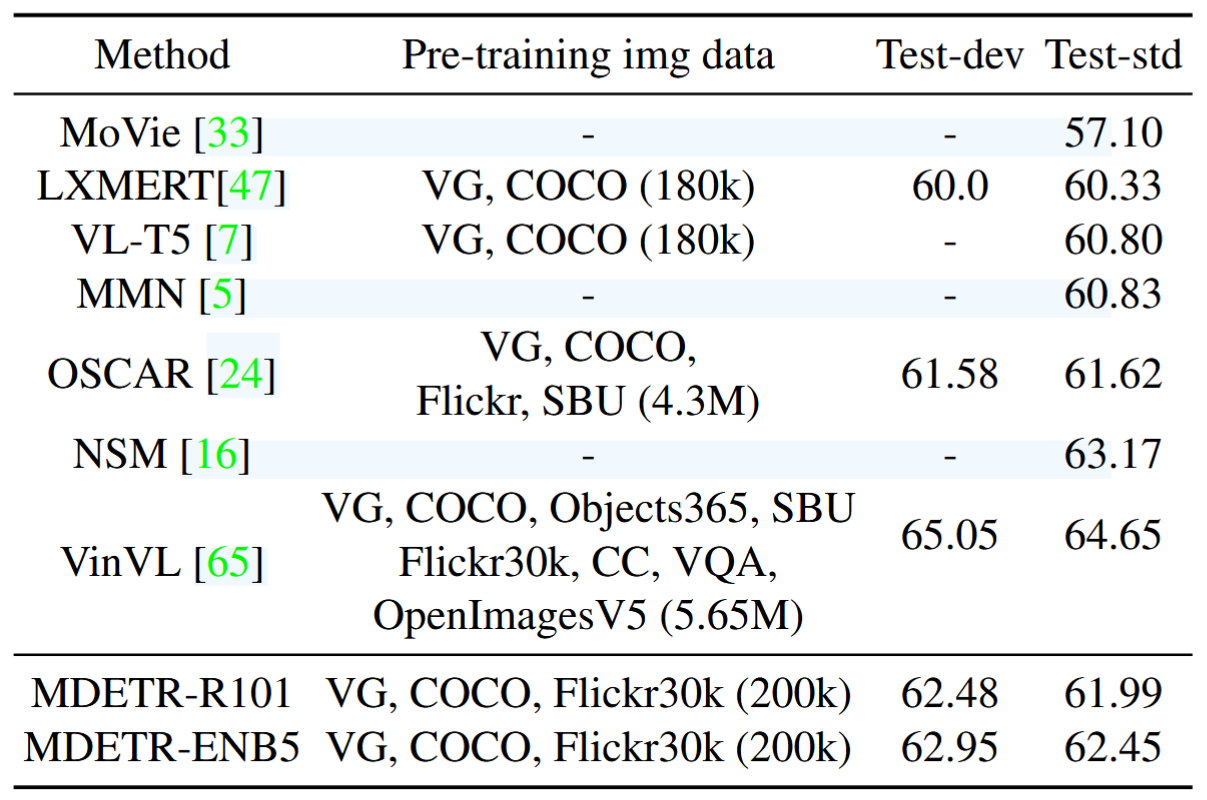
4. Visual Question Answering (VQA)
목표: 질문-이미지 쌍을 기반으로 정답 예측
전략: GQA에서 제공하는 scene graph로 단어-객체 매핑 얻어 학습, 추가 object query들 사용(100개는 detection용, 그 외는 질문 유형별로, 하나는 질문의 유형 예측용)
성과: 백본 ResNet-101 사용해도 LXMERT, VL-T5, OSCAR보다 우수. EfficientNet-B5 백본 사용 시 성능 추가 향상
5. Few-shot transfer for long-tailed detection
목표: 적은 수의 예시(few-shot)로 long-tail 객체 탐지 잘 하기
학습: 각 클래스 이름을 텍스트로 제공, 그 클래스가 존재하는 이미지에는 해당 박스 주석 제공
Few-shot 세팅: LVIS 학습 데이터셋의 1%, 10%, 100%만 사용해 학습 실험
추론: 모든 클래스 이름을 텍스트로 입력 -> MDETR가 박스를 예측 -> 모든 예측 박스 병합
결과: 1%의 경우 baseline DETR보다 훨씬 우수, 10%의 경우 AP=20.9(꽤 우수한 성능), 100%의 경우 오히려 감소(데이터 불균형(class imbalance)이 심해서 성능 악화)

4. Related Work
- CLEVR 기반 Reasoning 모델들
- 멀티모달 대규모 사전학습 모델들
5. Conclusion
MDETR 모델의 기여
- 멀티모달 이해에 뛰어난 성능 (자유형식의 텍스트에 따라 탐지 객체가 달라지는 modulated detection 수행)
- 다양한 다른 downsteam 작업에 적용 가능 (Phrase Grounding, Referring Expression Comprehension/Segmentation,
VQA, Few-shot Detection)
'AI' 카테고리의 다른 글
| MDETR 모델 주요 코드 분석 (0) | 2025.07.18 |
|---|---|
| [논문 리뷰] FedMSplit: Correlation-Adaptive Federated Multi-Task Learning across Multimodal Split Networks (2) | 2025.07.11 |
| [논문 리뷰] Towards Multi-modal Transformers in Federated Learning (4) | 2025.07.08 |
| [AI] 졸업 프로젝트 PreView: AI 서버 구축, RAG 초기 세팅 후 백엔드 API와 연결 (0) | 2025.05.19 |
| [AI] 졸업 프로젝트 PreView: GPT-4o fine-tuning하여 자기소개서 첨삭 모델 만들기 (0) | 2024.11.26 |


